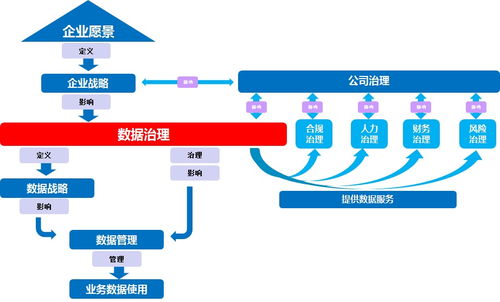
美團實時數倉的挑戰與應對 數據處理服務如何破局
隨著外賣、出行、酒旅等業務的高速發展,美團對數據實時性的要求越來越高,傳統的批處理數倉已難以滿足實時決策、實時風控和實時推薦等場景的需求。因此,美團投入大量資源構建實時數倉。在建設過程中,美團也面臨著一系列核心痛點,并在實踐中探索出一套行之有效的解決方案,特別是通過構建強大的數據處理服務來化解這些挑戰。
一、美團構建實時數倉的主要痛點
- 數據規模巨大且增長迅猛:美團業務覆蓋全國,每日產生PB級的交易、用戶行為、物流軌跡等數據。將如此海量的數據實時接入、處理和存儲,對系統的吞吐能力、計算能力和存儲成本構成了嚴峻考驗。
- 數據來源復雜多樣:數據來自數百個業務線、數千個數據表,格式各異(如MySQL binlog、日志文件、消息隊列數據等),協議和數據結構不統一,導致實時采集、解析和清洗的復雜度極高。
- 對數據質量和時效性的雙重要求:在實時場景下,既要保證數據處理的低延遲(通常要求秒級甚至毫秒級),又要保障數據的準確性、完整性和一致性。例如,風控系統對欺詐交易的識別必須在毫秒內完成,且不能有誤判或漏判。
- 技術棧復雜,運維難度大:實時數倉涉及Flink、Kafka、HBase、ClickHouse等多種技術組件,各組件間的集成、監控、故障恢復和性能調優需要專業團隊持續投入,運維成本高昂。
- 業務需求變化快:新業務、新活動頻繁上線,數據模型和計算邏輯需要快速迭代,要求實時數倉具備高度的靈活性和可擴展性。
二、解決方案:構建強大的數據處理服務
針對上述痛點,美團通過打造一套統一、高效、可靠的數據處理服務平臺來系統性地解決問題。
- 統一數據接入與標準化服務:
- 開發了通用數據采集框架,支持對各種數據源的自動發現、協議適配和格式解析。
- 建立了統一的數據Schema注冊和管理中心,強制推行數據標準化,減少后續處理的歧義。
- 利用消息隊列(如Kafka)作為統一的數據總線,實現數據的緩沖和解耦,確保高吞吐。
- 流批一體的計算引擎與低代碼開發平臺:
- 基于Apache Flink構建流批一體的計算核心,同一套代碼既可處理實時流數據,也可處理歷史批量數據,簡化開發并保證數據口徑一致。
- 提供可視化或SQL化的低代碼開發平臺,讓業務分析師和數據分析師也能快速配置實時計算任務,大幅降低開發門檻和迭代周期。
- 分層架構與實時OLAP服務:
- 采用經典的實時數倉分層架構:ODS(原始數據層)-> DWD(明細數據層)-> DWS(匯總數據層)-> ADS(應用數據層)。每一層職責清晰,便于管理和復用。
- 在ADS層,集成了ClickHouse、Doris等實時OLAP數據庫,為業務方提供亞秒級查詢響應的數據服務,支撐實時報表、即時查詢等場景。
- 全鏈路的數據質量與運維保障體系:
- 在數據處理服務中內置數據質量監控模塊,對數據的延遲、丟失、重復和準確性進行實時校驗和告警。
- 建立了從數據采集、計算到存儲的全鏈路監控和追蹤系統,能夠快速定位性能瓶頸和數據異常。
- 實現了計算任務的自動化部署、彈性伸縮和故障自愈,顯著降低了運維負擔。
- 成本優化與資源治理:
- 通過數據壓縮、冷熱數據分層存儲(如將歷史明細數據轉存至成本更低的HDFS)、計算資源動態調度等技術,有效控制存儲和計算成本。
- 建立資源配額和審計制度,確保數據處理服務資源的合理分配和高效利用。
美團構建實時數倉的痛點根植于其業務的超大規模、復雜性和高實時性要求。其破局之道在于不局限于單一技術的優化,而是通過構建一個涵蓋數據接入、計算、存儲、治理和服務的完整數據處理服務體系。這個體系以統一化、自動化和智能化為核心,不僅有效解決了當下的挑戰,也為未來更復雜的實時數據場景奠定了堅實的基礎。對于其他面臨類似問題的企業而言,美團的實踐表明,系統性的平臺化建設是應對實時數倉復雜性的關鍵。
如若轉載,請注明出處:http://www.ppdown.cn/product/46.html
更新時間:2026-04-02 16:11:22